이번 글은 저번 편에서 의문이 들만한 점들을 짚어주고 수식을 약간 사용할거야.
https://www.dogdrip.net/398692671
아직 안 읽었다면 꼭 읽고 오길 바래!
1. 왜 Q를 사용했을까? 현실 세계의 오류를 반영하면 되잖아.
이전 글에서 Q, 그러니까 확률값이 없는 정답을 사용하는 이유에 대해 잘 설명하지 않았던것 같아.
좀 더 정확하게 얘기하자면, 우리가 얻을 수 있는 데이터는 이 데이터밖에 없기 때문이야.
가령 동전을 던지는 상황을 예로 들어보자. 동전을 던지면 앞면 혹은 뒷면이 나오게 돼.
그렇다면 이 동전의 P는 뭘까?
다들 너무나 당연히 알고 있지?
동전의 P = {앞면 = 50%, 뒷면 = 50%}
그렇지만 우리는 머신러닝을 사용한다고 했잖아. 그럼 마찬가지로 수학문제와 정답을 알려줘야 해.
여기서는 문제와 정답이 뭘까? 혹시 정답이 P 아니냐고 할 수 있는데 헷갈리면 안돼. 여기서는
수학문제 : 던지는 행위, 정답 : 앞/뒤 여부
야. 문제는 어떻게 보면 조건에 가깝다고도 할 수 있겠네.
그럼 좀 이해가 돼? 우리는 동전을 던져서 앞 뒤가 몇번 나왔는지를 보고 동전의 P를 짐작해야 해.
이게 바로 머신러닝이자 딥러닝인거야.
그러면 이 문제는 동전을 몇 번 던지느냐에 따라 정답률이 나오게 되겠지.
아니면, 동전을 우연히 100번 던져도 100번 다 앞면이 나와버릴 수도 있어.
그럼 이게 '동전을 던지는 행위'인걸 모른다고 가정할 땐, 당연히
추정된 동전의 P~ = {앞면 = 100%, 뒷면 = 0%}
가 되는거야.
동전은 아무 잘못이 없어. 순전히 확률에 의해 던져진것 뿐인걸?
단지 아주 낮은 확률로 100번을 던질 때 100번 다 앞면이 나와버린 것 뿐이고, 이 데이터를 얻은 개붕이는
P~를 저렇게 추정해버린 것 뿐이야.
이렇게 얻은 데이터를 기반으로 제일 가능성이 높은 P~를 추정하는 것이 바로
Maximum Likelihood Estimation (줄여서 MLE) 과 Monte Carlo method를 섞은 방법이야.
(* MLE를 정확하게 수행하는 방법은 무한개의 데이터에 대한 적분이므로, 유한개의 데이터를 사용한 Summation으로 문제전환하는 것이 Monte Carlo method)
그럼 이렇게 질문하는 개붕이들이 있을수 있겠어.
내가 이전 글에서 썼던 오류는 그렇다면 순전히 확률에 의한 거잖아.
그건 엄밀하게 오류라고 볼 수 없지. 위 재수없는 동전 사례랑 똑같은거잖아.
단지 재수없는 동전은 P라는 규칙에 따른거고, 정말 재수없는 개붕이는 그 데이터를 얻어버린거고.
현실 세계에서도 똑같은거 아냐? 이 오류란건 개붕이의 데이터가 재수없을 뿐이지.
맞아. 전편에서 말했던 오류는 실제론 오류가 아니야. 순전히 확률에 의거한거지.
그럼 이전 글에서 사용했던 소제목 어그로도 수정해야겠어.
현실 세계의 데이터는 확률적이고, 재수가 없을 상황이 있다.
확률을 사용하면 재수가 없는 상황을 어느정도는 타파할 수 있다.
2. 그래서 Q를 이용해서 P~를 어떻게 구한다는건데?
이전 글에 썼던 내용을 다시 상기해볼까?
바로 KL 다이버전스라는 장치가 있는데, 이 장치를 사용하면 P~는 Q를 모방하게 되지만, Q와 동일해지지는 않아.
KL 다이버전스는 정말 간단한 수식이야.
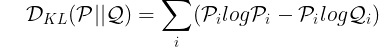
?
아 미안 ㅎㅎ 설명을 해볼게. 저기서 i는 사건의 종류를 의미해.
여기선 P와 Q로 비교했지만, 우리는 추정된 동전의 P~와 동전의 P로 비교해볼까?
D_KL(P || ~P) = 앞면일 때 (PlogP - Plog~P) + 뒷면일 때 (PlogP - Plog~P)
= 1/2 log1/2 - 1/2log1 + 1/2 log1/2 - 1/2 log0
어... 미안 어쩌다보니 log0이 나와버렸는데, 실제로 계산할때는 편의상 0 대신 아주 작은 값을 넣어.
아무튼간에 이걸 쓰면 P~와 P의 차이를 구할 수 있어.
그리고 각 사건에 대한 확률 차이 (확률 분포의 차이) 도 정확하게 계산해주지.
근데 그 차이를 계산하기만 하면 뭐해. P~를 다시 계산해줘야 하잖아.
그래서 우린 이런 수식을 정의할 수 있어.

뭐냐하면, 데이터 i에 대해 P~와 Q의 KL 다이버전스를 계산하고
우리가 수집한 모든 데이터 N에 대해서 모든 KL 다이버전스를 구한다면,
모든 데이터에 대해 P~와 Q의 차이를 구할 수 있겠지. 이걸 'Loss'라고 정의를 한다면

이렇게 Loss를 최소화하는 방향으로 학습한다면
P~와 Q는 동일해질거야. 이걸 Empirical Risk Minimization (ERM) 이라고 불러.
어떻게 동일해지냐구? 그건 이분이 잘 써놓으셨더라고.
역전파 방법 및 SGD라는걸 사용하면 이 Loss를 정의한 것 만으로 딥러닝은 아주 잘 학습해. 정말 놀라울 정도로!
이건 딥러닝의 마법 정도로 생각해도 무방할것 같네.
( * 실제로 딥러닝에선 KL 다이버전스대신 크로스 엔트로피를 쓰지만, 크로스 엔트로피와 KL 다이버전스를 최소화하는건 동일한 문제에 해당해서 스킵했어)
3. 그럼 아주 많이 학습한 딥러닝이 최강일까?
아니.
위에서 언급한 Loss가 최소화되는 방법은 오로지 P~와 Q가 동일할 때야.
하지만 우리가 구하고 싶은건 P잖아? Q를 구하는게 아니라구.
게다가 우리가 얻은 데이터는 실세계에서 구할 수 있는 만큼 구한 약간의 데이터지, 실세계의 모든 데이터가 아냐.
따라서 약간의 데이터에 대해 100%의 확률이라고 큰소리치는 Q를 얻는다고 해서, 실세계의 다른 데이터에 대해서도 정확하게 추론할 수 있는것도 아니거든.
설사 실세계의 모든 데이터를 얻는다고 해도 P를 정확히 구하는 건 불가능해.
위에 있는 동전 던지기 문제를 생각해봐. 동전의 P를 구할 수 있는건 동전을 무한번 던져야만 가능한거거든.
따라서 제일 간단하고 효율 좋은 방법은
실세계의 데이터 약간을 가져와 거기에 대해 Q와 P~의 Loss를 어느정도 줄이도록 학습한 다음
또 다른 데이터 약간을 가져와 학습된 P~와 Q의 Loss를 계산하는거야.
이 때 학습하지 않은 데이터에 대해 Loss가 가장 적을 때 제일 좋은 P~라고 할 수 있어.
왜냐하면 실세계의 데이터에 대해 제일 잘 추론할 확률이 높다는거고, 그 말은 P에 제일 근사하다는 뜻이거든.
다음에는 내가 설명한 기초 이론을 잘 버무린것만으로 놀라운 성과를 달성한 mixup이란 논문에 대해 설명해볼게.
내가 쓴 글만 이해했다면 전혀 어렵지 않을거야!



ptrtype01
신경망 학습과정은 너 안쓰면 내가쓸까
single perceptron, xor problem, multilayer, background propagation, optimizers, loss functions 정도 불릿잡고 쓰면 될것 같은데
사이에 activation function들 소개하면서 gradient vanashing도 넣으면 괜찮을것 같은데
그렇게 쓰고 2부에선 tf없이 단순 파이썬만으로 신경망 만들어보기 이런거 할까ㅋㅋㅋㅋ
lIIIIllIlIl
와...그건 다 못쓰겠다 너가 써줘.... 난 mixup 다루고 재밌는거 없으면 쉴생각임
어헛우훗
재미지것다!!
박데방
첫번째로, 통계에 대해 관심이 많아서 공부하고 있는데 이런 양질의 정보 글을 읽을 수 있다는 거에 감사하다는 인사부터 전할게,
아직 공부를 시작한지 얼마 안 됐기도 하고, 머신러닝, 딥 러닝 들어가기 전에 통계 공부부터 하자고 생각이 들어서 회귀분석부터 차근차근 공부하는 중인데, 첫번째와 두번째 글을 읽어보니까 들은 생각이 있어. 결국에는 모수의 분포를 알아내는게 딥러닝을 하는 이유로도 보이는데, 모수의 분포를 알아내는 건 앞서 나왔던 MLE 같은 방식 같은 전통적인 통계 방식(컴퓨터의 힘을 빌리지 않는)으로도 유추가 되는 것 같은데, 이를 굳이 딥러닝으로 돌려야 하는 이유가 있을까? 아니면 딥러닝 같은 방식이 훨씬 획기적인 퍼포먼스를 보여주는 걸까?
아직 내가 ML이라 딥러닝을 공부해보지 않아서 드는 생각인 거 같아. 정말 관심이 많은 분야인데 이렇게 글 써주니까 계속 재밌게 읽고 있는 중!
lIIIIllIlIl
아주 난해한 함수를 fit하는데 좋기 떄문임. 전통적인 통계 방식은 텍스트나 이미지처럼 고차원의 데이터에 대해 loss를 감소하는 방향으로 학습하기 어려웠음. 계산량이 너무많기 때문에. 근데 딥러닝은 차원 수가 높은 데이터라도 구조만 잘 잡으면 loss를 감소시키는 방향으로 잘 학습하기 때문인듯. svm이라고 특징을 잘 변환하는 모델이 있는데, 딥러닝은 그거보다도 특징을 잘 변환함
오늘가입했습니다
내말이 이말임 ㅋㅋ
오늘가입했습니다
현실의 데이터는 훨씬 더 복잡해서. 사실 간단한 분류는 Svm같은것도 잘함 ㅋㅋ
barcode4421
MLE 는 어떤걸 maximize 할지 결정하는 거지, function form 을 결정하는게 아님
즉 아주 간단한 probabilistic model 로도 MLE 를 할 수도 있고 딥러닝 처럼 엄청나게 param 이 많은 모델로도 할 수 있음.
deep learning 이 기존 ML 모델들과 다른 점은 엄청나게 많은 parameter 를 가지고 이를 통해서 어떠한 복잡한 함수도 모델링 할 수 있기 때문. 그리고 이를 가능케하는 GPU의 발전 덕 (10년 전만 해도 지금 가장 작은 모델도 한번 학습하려고 3달동안 돌려야 했음)
혜워녜나
회귀분석을 봤다니까 대충 그 선에서 비유해서 말하자면
딥러닝은 회귀분석을 차원 늘려서 겁나 여러개 돌린거야
모수의 분포가 상상 못할 다차원으로 구성되어 있으니까 그들중 뭐가 더 중요한 분포인지도 찾는거야
굉장히 상식적인 단계인데 처음 출현하고는 컴퓨팅 파워가 못따라가서 한참 사장되어 있었어.
근데 현대에 들어와서 계산 가능한 수준이 되니까 다시 나타난거임.
유부남
똑똑들 많은 개드립
말안통함
난 개인적으로 svm 쓰는 이유를 잘 모르겠던데... 속도도 존나 느리고 얻을 수 있는 statistical inference도 낮고 뭐 서포트 벡터를 주긴 하지만 그게 다른 방법보다 데이터를 설명하기에 직관적인가? 그래서 좀 애매한 느낌... 데이터 해석하려면 더 간단하고 빠른 직관적인 모델들 많고 분류 성능 높이려면 더 효율적인 모델 많은데 왜 굳이 svm...? 싶은데 어떻게 생각함?
오늘가입했습니다
ㅇㅇ 그래서 svm망함. 사실상 뉴럴 네트워크에서 액티베이션 뺀게 svm이라서
말안통함
뭐 클래식한 방법 중에선 nn 제외하고는 성능과 regulization에 뛰어나서...?
barcode4421
학계에서 SVM 을 그대로 쓰는 사람은 아무도 없음. 10년 전 메서드인데 그걸 어케 그대로 써
그렇다고 의미가 없는게 아니라 max margin 이나 kernel trick 같은거는 딥러닝에서도 적용하는 페이퍼 많음
(물론 커널 같은건 implicit 하게 deep learning 이 알아서 해주긴 하지만 직접적으로 formulation 하는 경우도 있다는뜻)
말안통함
SVM kernel로 Feature engineering 한다는거지?
barcode4421
ㄴㄴ SVM 알고리즘 자체가 굉장히 오래된 알고리즘이라 그거 자체로는 성능차이가 엄청나게 많이나서 svm feature 를 직접 쓰는건 아니고 딥라닝 모델에다가 svm 에서의 아이디어를 얹어서 쓰는거.
말안통함
맥스 마진이야 그렇다 쳐도 kernel trick이 svm에서 나온 아이디어는 아니지 않음? 커널 트릭이 svm에 쓰이긴 해도 그걸 svm에서 나온 아이디어라고 봐야하나? Svm kernel도 아니라니까 좀 헤깔리네...아님 내가 모르는 부분이 있나봐
lIIIIllIlIl
https://www.reddit.com/r/MachineLearning/comments/2ffejw/why_dont_researchers_use_the_kernel_method_in/
이 글 잘나온듯 한번 읽어보셈
말안통함
어...걍 서로 이해가 잘 안됐던거 같네.. 난 커널트릭이랑 svm이랑 별개의 개념이고 커널트릭이 svm에서 나온거도 아닌데 (걍 가장 유명한 적용 예?) svm에서 나온 아이디어를 딥러닝에도 적용하는것 처럼 이해해서 '그 둘이 도대체 뭔 상관인데..' 했던거고...
나도 용어 선택을 제대로 못한듯.
뭐 결국 커널 트릭을 svm에 적용하기 용이하고, 커널 모델링해서 svm 에 적용하면 알아서 다 해주는 블랙박스인 딥러닝보다 데이터 해석과 모델 검증에 용이하다는거네.. 에잉
barcode4421
Flow-based model 을 제외하면 커널을 handcrafted 로 만드는 경우는 없다고 봐야됨
deep learning 한다면 svm 은 그냥 머리에서 지워버리셈
말안통함
그렇구나ㅎㅎ 글겠지 뭐...과학자들처럼 모델링과 이론 검증이 필요한 사람들 아니면 커널 파라미터 일일히 다 조정해가며 하는 사람은 없겠지..
난 딥러닝이나 머신러닝이 내 전공은 아니라ㅎㅎ.. 너는 학생이야? 아님 데이터 싸이언티스트로 일하는 중?
lIIIIllIlIl
특징변환을 아주 빠르고 쉽게 함. 근데 svm은 목표 loss에 따라 특징변환하지 않고, 딥러닝은 목표 loss에 따라 특징변환함. 대신 딥러닝은 계산량이 많아서 처음엔 svm이 많이 쓰인거임
ric
nn 나오기 전에 경험을 되집어 보면...
최적의 모델이라기보단 가장 범용적인 모델이라서 그런거 같음.
kernel, discriminative 두가지 특징 떄문에 데이터 특성을 가장 덜 타던걸로 기억함.
discriminative model이라서 boundary근처 데이터만 충분하면 전체 데이터가 bias 되어도 되고
kernel 사용해서 non-linear한 상황도 커버가 되고
그래서 뭔 task던 간에 일단 svm 때려보고 base로 썼었음 ㅋㅋ
(연속 데이터면 svm, 이산 데이터면 maximum entropy)
말안통함
그래서 어르신들이 svm부터 때려넣어보고 시작하는거구나...
착한말착한말
그레이의4000가지그림자
ric
MLE가 적분이었던가??? 나 숙제할 떈 맨 편미분만 했던거 같은데.....
lIIIIllIlIl
나도 좀 찾아봤는데 로그우도 수식은 적분 혹은 유한개 데이터에 대해서는 summation
이걸 통해 직접 파라미터 구하는게 편미분
ric
아아 sum 했던거 기억난다 ㅋㅋㅋ
아멜리아왓슨
문돌이라 하나도 이해안되는데
대충 현실데이터를 통한 딥러닝에 둘다 섞은 딥러닝딥러닝을 섞으면 요상한 조화?로 아무 손해없이 추론율이 50% 뚫고 상승한다는거지? 결과적으로 퍼포먼스가 75%~99% 라는거임? 이세돌은 신이다
lIIIIllIlIl
아 음...... 그래 음
어헛우훗
이런글은 보면 초심자보라고 쓴거같은데 막상 초심자는 안보고 고인물들만 와서 학회형성중임 ㅋㅋㅋ나는 제어연구하는데 비선형시스템을 근사하기위해 nn을 쓰는정도라 깊게 공뷰는 잘 안했음
lIIIIllIlIl
ㅜㅜ 그러게 많이 어려운가
어헛우훗
초심자들은 그냥 보다가 스크롤 내리고 가고 전공자들은 하나하나 다읽고 의견내고 그런다는거지 ㅋㅋㅋ난 겉할ㅋ기로만 아는정도인데도 이해하려면 꽤 시간을 써야할거같아
어헛우훗
정독하고 모르는거 다 물어봐도되나
lIIIIllIlIl
ㅇㅇ물어보셈
Erino
신기하다
중간쯤 읽다가 잠들뻔햤어 ㄷㄷ
lIIIIllIlIl
Erino
미아내
뭔소린지는 알지만 수식 보니까 졸려...